Downloading HTML5 games for offline play
So, I was nerd-sniped on Reddit a bit over a week ago.
Someone posted on r/webdev asking whether it would be possible
to archive a certain HTML5 game locally for offline play, similar to how folks
used to archive Flash games by downloading the embedded .swf file, back in
the early days of the Web. None of the other answers seemed particularly helpful
at the time, so I decided to take a stab at it.
Below is a recounting of my original thought process while approaching this problem, from beginning to end.
Disclaimer: This post is intended for educational and non-commercial fair use purposes only. If you’re impatient, skip ahead to the TL;DR section for a list of steps.
A first attempt§
First, let’s take a brief look at the game itself:
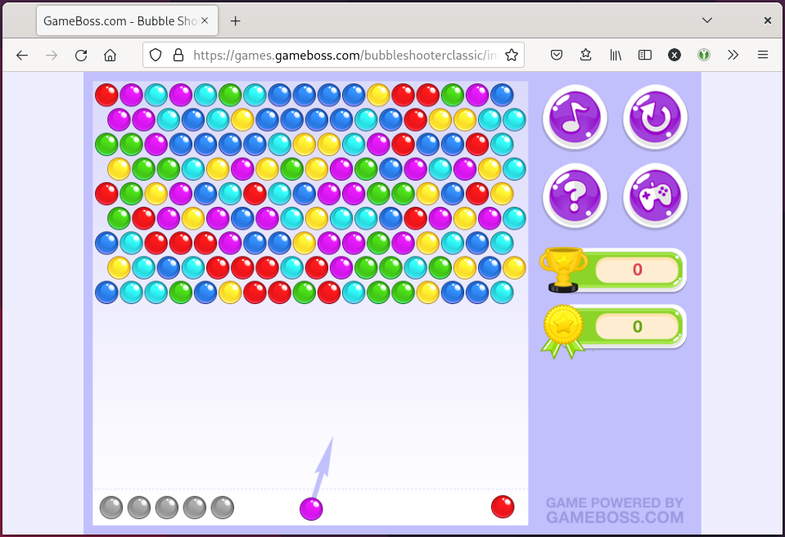
Seems like a simple enough single-player game with no server-side networking features. This should be an easy task, then!
I’ll hit Ctrl+S in Firefox to save the entire Web page, including any
referenced assets, open the index.html, and…
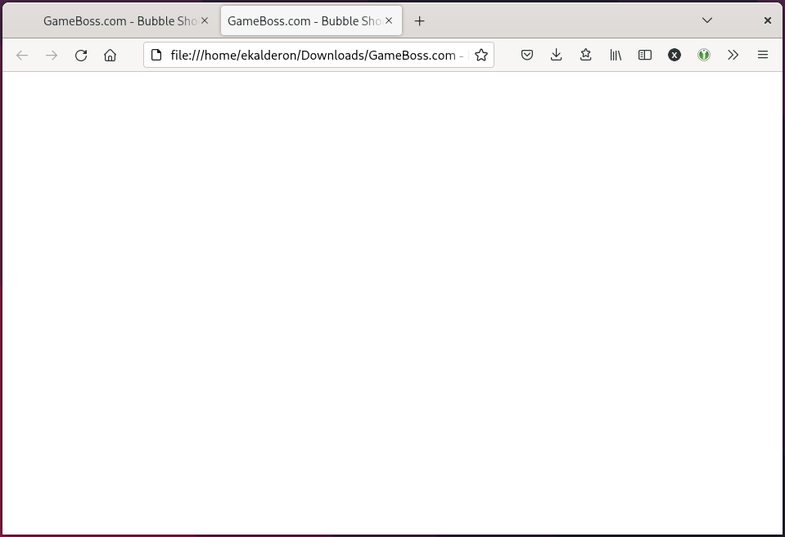
A blank page. That’s odd. I wonder why?
Popping open the debug console with F12 reveals that the game is missing a bunch of resources.
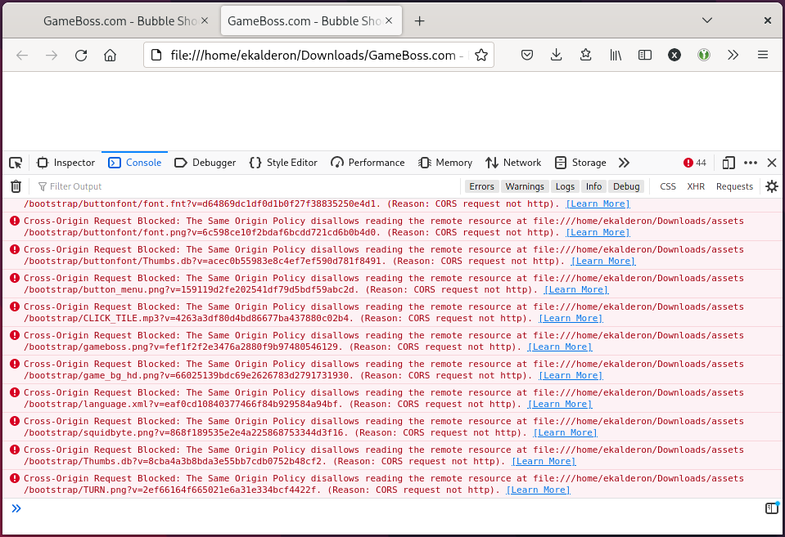
CORS errors aside, the
resources aren’t even loading in from the ~/Downloads/GameBoss_files directory
that Firefox had created; their paths are instead relative to ~/Downloads.
Looking through the index.html source, I see the following <script> tags:
<div ...>...<script async="" src="GameBoss_files/main-html.js"></script></div>
<script src="GameBoss_files/flambe.js"></script>
<script>
flambe.embed(["targets/main-html.js"], "content");
</script>
That’s not right. Looks like Firefox failed to detect "targets/main-html.js"
in the inline JavaScript and didn’t rewrite it to
"GameBoss_files/main-html.js" when saving the webpage with Ctrl+S.
Fixing this and reloading the page doesn’t seem to do any good.
This flambe.js script that’s being loaded alongside main-html.js looks
interesting, though. The name seems to refer to
Flambe, a 2D game engine written in
Haxe that deploys to HTML5.
Going back into the devtools again, let’s switch to the debugger and inspect the
source code for main-html.js. This is probably where the actual game logic
lives, since I presume flambe.js contains the base game engine.
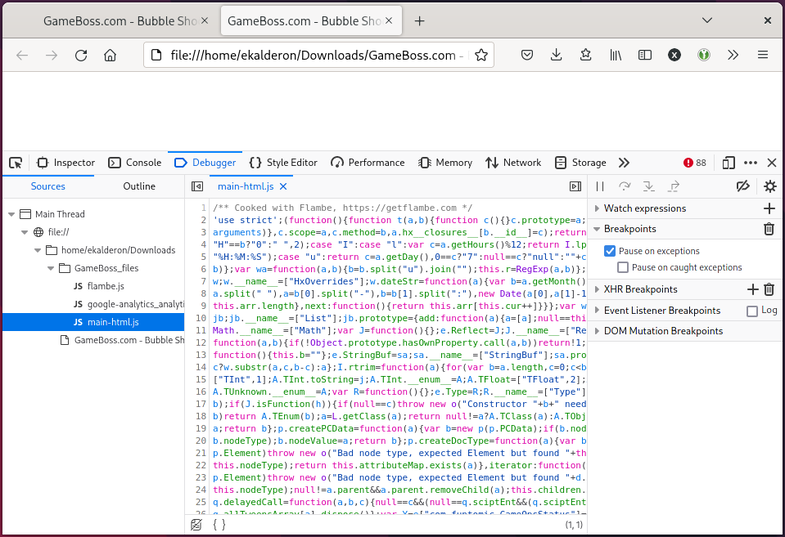
Ouch, that’s hard to read. Let’s pretty-print that code…
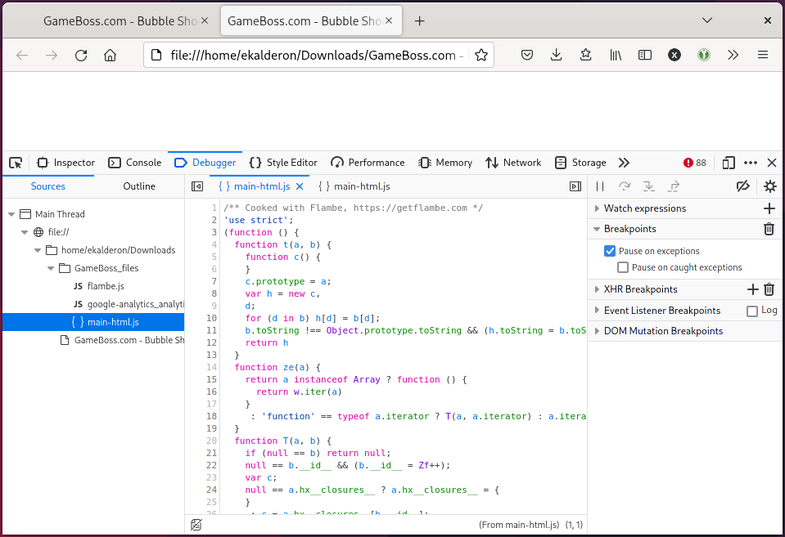
Much better! 👍 Searching for the word “assets” in the open file, I find a promising-looking section towards the bottom:
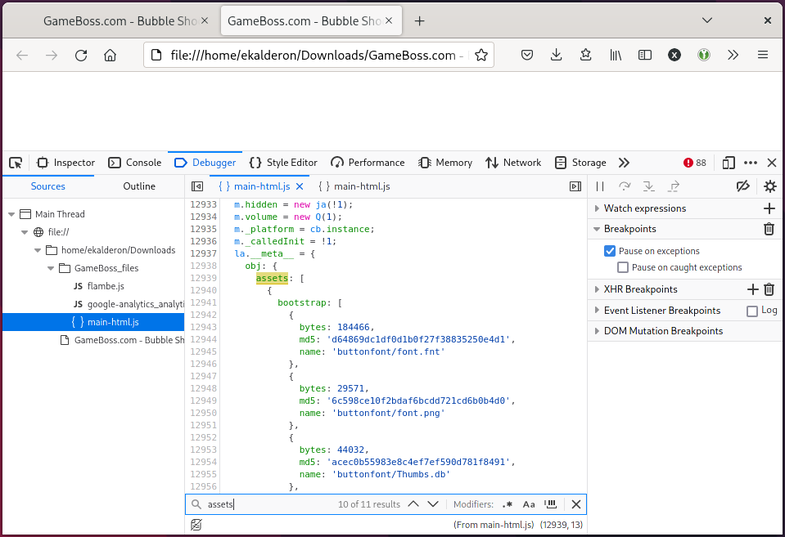
This nested __meta__ object field appears to contain all the game assets, and
is organized into the following structure:
assets
├── bootstrap
│ └── ...
└── hd_assets
└── ...
Each entry contains the asset’s path (relative to the game’s root URL), its size in bytes, and an MD5 hash digest, presumably for verifying the file’s integrity. Below is an example entry:
{
bytes: 18446,
md5: 'd64869dc1df0d1b0f27f38835250e4d1',
name: 'buttonfont/font.fnt'
}
Honestly, the task of downloading each and every file by hand and arranging it into the correct folder structure seems daunting. There may also be other broken paths in the code or assets that I’m unaware of, complicating things. Fixing all this up would be tedious enough on its own, much less teaching an Internet stranger how to do it.
I decided to leave a comment directed at the OP explaining the complexity of the task at hand and asked “why not use a Wayback Machine capture of the game instead?” It seems perfectly functional, and this link is guaranteed to last as long as Archive.org itself exists as an organization (which is hopefully a good long while; please donate to them).
It turns out it was OP who created this particular Wayback Machine capture in the first place! This was done prior to posting their question in r/webdev. While this does indeed preserve the game for the future, they didn’t like how slowly the archived page loaded and were wondering if totally offline play was possible. So we’re back to square one: how can we archive this game?
Wait a minute… If downloading the game files directly from the publisher’s website is unreliable due to broken paths and missing assets, then maybe we could download it from the Wayback Machine instead? Its client-side URL rewriting capabilities are very advanced1, so surely it will have managed to capture all the necessary files. Perhaps this approach might work better?
Starting again, a new lead§
Rather than naively downloading the Wayback Machine capture of the game using
Ctrl+S again and potentially suffer the same issues as before, I
want to try a third-party tool named wayback-machine-downloader instead.
This seems to do exactly what I need!
Switching to a new directory in the terminal, let’s install the Ruby gem and run
it against the live website, being careful to leave off the index.html at the
end so it fetches the whole bubbleshooterclassic directory rather than just
the one file.
gem install wayback_machine_downloader
wayback_machine_downloader https://games.gameboss.com/bubbleshooterclassic/
Success! Looks like it found the capture and is grabbing the files.
Downloading https://games.gameboss.com/bubbleshooterclassic/ to websites/games.gameboss.com/ from Wayback Machine archives.
Getting snapshot pages.. found 92 snaphots to consider.
79 files to download:
https://games.gameboss.com/bubbleshooterclassic/ -> websites/games.gameboss.com/bubbleshooterclassic/index.html (1/79)
...
Download completed in 111.17s, saved in websites/games.gameboss.com/ (79 files)
Okay, now that the download has finished, let’s see what we’ve got here:
$ tree ./websites/games.gameboss.com/
websites/games.gameboss.com/
└── bubbleshooterclassic
├── assets
│ ├── bootstrap
│ │ ├── buttonfont
│ │ │ ├── font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1
│ │ │ └── font.png?v=6c598ce10f2bdaf6bcdd721cd6b0b4d0
... ... ...
Alright, looks promising. Let’s try to open the index.html in the browser
again…
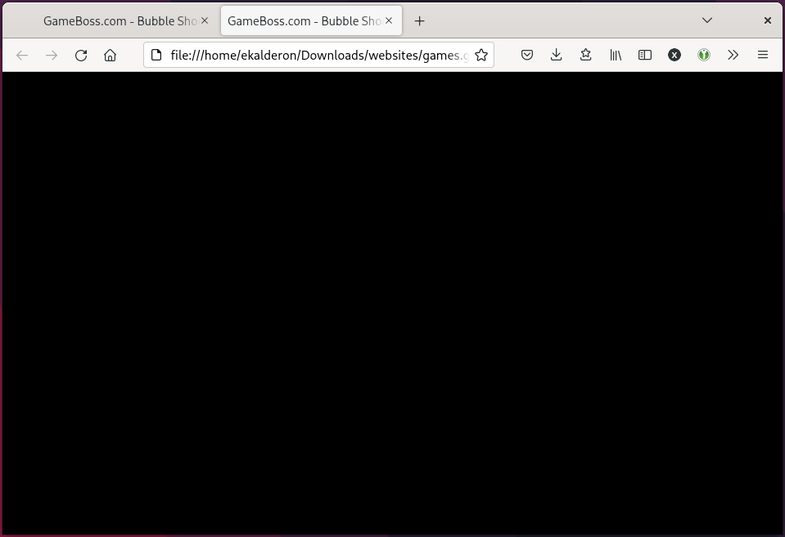
Well, a black screen instead of a white screen is an improvement, I guess. I suppose I should’ve expected something to still be wrong.
Let’s check the console again…
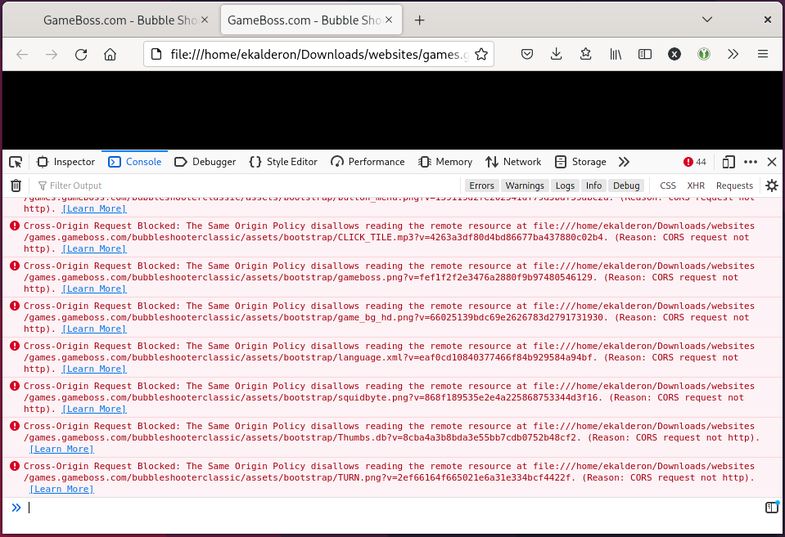
Ah, right. We still haven’t resolved the cross-origin GET errors we were
seeing before. There are two possible ways to approach this problem:
- Disable CORS enforcement at the browser level.
- Serve the game locally on an HTTP server that attaches a
Access-Control-Allow-Origin: *header to every response sent.2
The first option would be nice in theory, since it would allow anyone to
double-click on the index.html in their file browser to open and play the
game. However, this is infeasible in practice: the process of disabling CORS
enforcement works slightly differently for every major browser. Some, like
Mozilla Firefox, don’t even allow users to broadly disable CORS checks anymore
for security reasons (the security.fileuri.strict_origin_policy key still
exists in about:config, but its scope is too narrow to be useful here).
Besides, we don’t want to persistently override CORS for all sites; that could
be a security risk.
That leaves option two. While more complex than option one, this is a more targeted solution that is guaranteed to work equally across all major browsers, isn’t a potential security risk, and is nonetheless easy enough to do.
This short Python script
should do nicely in a pinch. It does exactly what it says on the tin: it serves
all the files present in the current working directory on http://0.0.0.0:8000,
and crucially, it appends an Access-Control-Allow-Origin: * header to every
outgoing response, which should nullify those CORS checks currently preventing
the game from loading.
Let’s save the script as launch_game.py in the
websites/games.gamesboss.com/bubbleshooterclassic/ directory, which contains
the index.html and all the files we want to serve. We can then start the Web
server, like so:
python3 launch_game.py
This prints the following prompt and then hangs:
serving at port 8000
Okay, the server should now be listening on port 8000 on 0.0.0.0, which
effectively means all available network interfaces, including the loopback
device. Let’s nagivate to http://127.0.0.1:8000 in a browser window, then, and
see what we have.
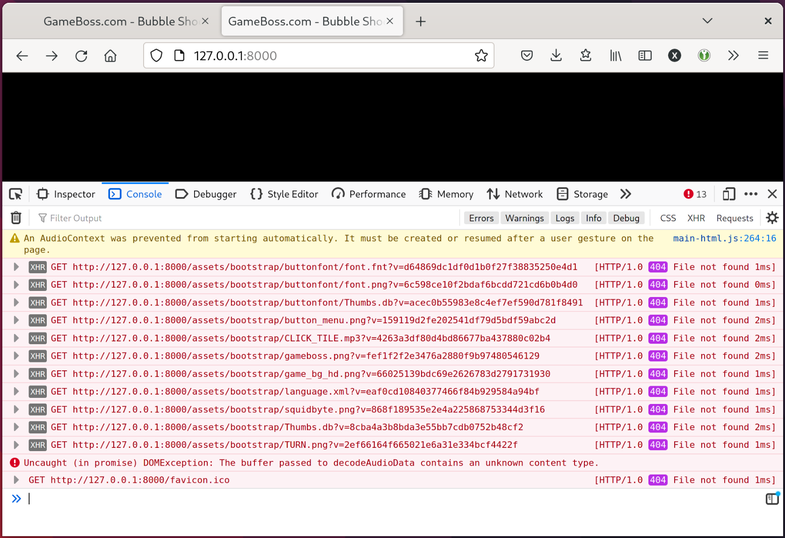
Darn. Thankfully, those pesky CORS errors are gone, but they have been replaced
with 404 File not found responses instead. Attempting to navigate to one of
the failing resource URLs in a new browser tab, such as:
http://127.0.0.1:8000/assets/bootstrap/buttonfont/font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1
(predictably) results in a 404 error as well.
But if we check the websites/games.gameboss.com/bubbleshooterclassic/
directory again, we see that the font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1
file we’re looking for is indeed present and in the right place.
$ tree ./websites/games.gameboss.com/
websites/games.gameboss.com/
└── bubbleshooterclassic
├── assets
│ ├── bootstrap
│ │ ├── buttonfont
│ │ │ ├── font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1
│ │ │ └── font.png?v=6c598ce10f2bdaf6bcdd721cd6b0b4d0
... ... ...
So what’s going on? The destination files exist, so why aren’t they loading?
Wait a minute… I think the literal ?v=... suffixes in the filenames
generated by wayback_machine_downloader are causing the GET requests to
fail. That is, any attempt to GET a file called
font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1 would result in a server-side
lookup of a file called font.fnt with the query string
v=d64869dc1df0d1b0f27f38835250e4d1.3 Since there is no file named
font.fnt at that location, the server responds with a 404 error.
In that case, what if we were to percent-encode the font.fnt?v=... portion
of the URL and try to wget that in the terminal?
$ wget http://127.0.0.1:8000/assets/bootstrap/buttonfont/font.fnt%3Fv%3Dd64869dc1df0d1b0f27f38835250e4d1
--2022-11-20 23:23:33-- http://127.0.0.1:8000/assets/bootstrap/buttonfont/font.fnt%3Fv%3Dd64869dc1df0d1b0f27f38835250e4d1
Connecting to 127.0.0.1:8000... connected.
HTTP request sent, awaiting response... 200 OK
Length: 184466 (180K) [application/octet-stream]
Saving to: ‘font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1’
font.fnt?v=d64869dc1df0d 100%[================================>] 180.14K --.-KB/s in 0s
2022-11-20 23:23:33 (458 MB/s) - ‘font.fnt?v=d64869dc1df0d1b0f27f38835250e4d1’ saved [184466/184466]
Aha! That works. So that confirms the hypothesis appears to be correct. Let’s
strip off all the ?v=... suffixes from all the filenames and see if that fixes
the issues we’re seeing.
So how should I do this? Back in my terminal window, I can recursively list all
game files that contain a literal ? in their names using a bit of Bash:
$ cd ./websites/games.gameboss.com/bubbleshooterclassic/
$ find . -name "*\?*" -type f
./index.html?lang=ru
./index.html?lang=en&gp=1
./index.html?lang=fr
./assets/hd_assets/prompt_bg.png?v=bdd07c452aa91dd9309717032b9a30d1
./assets/hd_assets/button_prompt_over.png?v=1c7d1e960c33bc02819c19b5c39e3673
...
I’d like to chop off every character from the ? character onward. Given this
list of filenames, we can pipe it through cut -d? -f1 to do exactly that.
$ find . -name "*\?*" -type f | cut -d? -f1
./index.html
./index.html
./index.html
./assets/hd_assets/prompt_bg.png
./assets/hd_assets/button_prompt_over.png
...
Now I’d like find to execute the mv command on each of those files, renaming
each one to the cut down version. Here’s the working solution I came up with:
find . -name '*\?*' -type f -exec bash -c 'mv $1 $(echo $1 | cut -d? -f1)' bash {} \;
Well, there seem to be no errors. Let’s check the output of tree to confirm.
$ tree
.
├── assets
│ ├── bootstrap
│ │ ├── buttonfont
│ │ │ ├── font.fnt
│ │ │ └── font.png
... ... ...
Sweet! Looks like all the filenames have been fixed, and not a single file with
? in its name is in sight. With the HTTP server still running, let’s switch
back to Firefox, refresh the page for http://127.0.0.1:8000, and see what
happens…

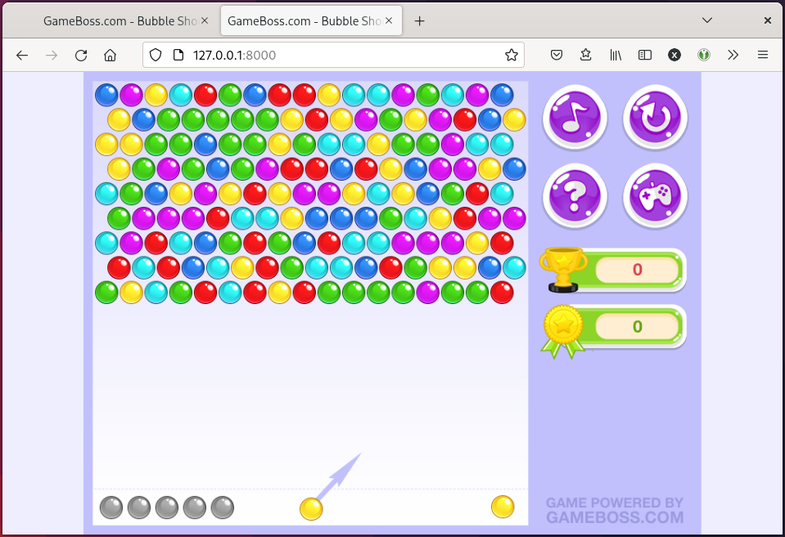
Finally! 🎉 Now that’s what I like to see. The game seems to be working.
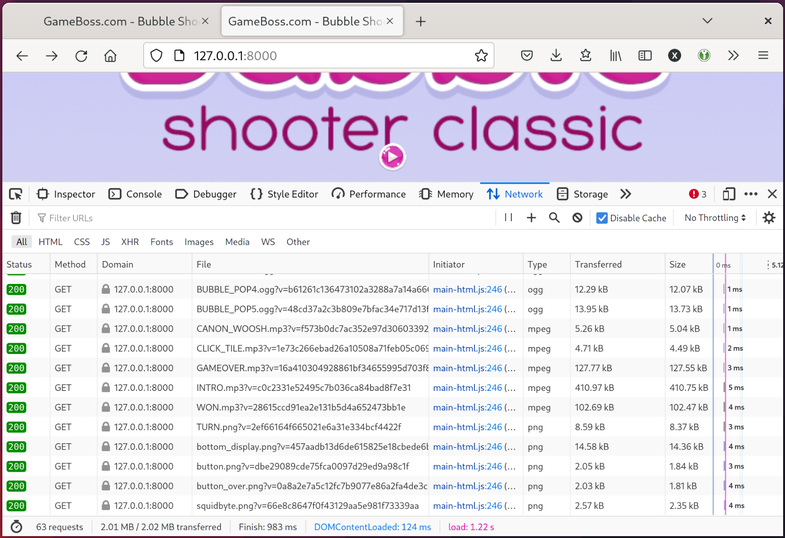
Popping open the devtools once more and switching to the “network” tab, I can confirm there are zero requests reaching out to the broader Internet and the game is running 100% locally:
That was so much fun! Now to relay what I’ve learned back to OP…
Conclusion§
Well… that was certainly more complicated than hitting Ctrl+S. 😅 Still, I had a lot of fun working through this project, and I learned a lot along the way.
These deeply satisfying rabbit holes and the occasional success story remind me of why I love computers in the first place. This also takes me back to formative childhood experiences playing Flash games on early 2000s sites like Weebl’s Stuff, Newgrounds, Miniclip, Albino Blacksheep, DeviantArt, and so on. Such moments are fleeting, and it’s hard to relive them today due to all the broken links, abandoned sites, and obsolete media formats.
When Adobe formally dropped support for Flash Player in 2020, it
sent ripples through these online communities. Everyone knew this was a long
time coming, and Shockwave Flash was on its deathbed for years, but at least
those old Flash games were still easy to preserve: all you needed to do was grab
the .swf, get yourself an old copy of Flash player or a modern emulator like
Ruffle, and you’re ready to go.
Modern HTML5 games are significantly more complicated to preserve due to all the added complexity, and this particular example I described, while ultimately successful, is hardly the norm. Today, it is the responsibility of Web game developers and game engine developers to design their games with historical preservation in mind, or else risk one day being forever lost to history.
Now, if you’ll excuse me, I’m off to play some Line Rider 2.
TL;DR§
Below is the final set of steps I eventually arrived at to download and run the game offline:
- Install Python 3 and Ruby, if you don’t already have them on your machine.
- Confirm there exists a Wayback Machine capture of the HTML5 game you would like to archive.
gem install wayback_machine_downloaderwayback_machine_downloader <live game url>- This saves everything to
websites/<domain>/path/to/game/. - Make sure to grab
/rather than/index.html. This ensures all the capture files get fetched and not just theindex.htmlfile.
- This saves everything to
- Strip the
?v=suffixes off all the filenames, if there are any.find . -name '*\?*' -type f -exec bash -c 'mv $1 $(echo $1 | cut -d? -f1)' bash {} \; - Save this GitHub Gist
in
websites/<domain>/path/to/game/aslaunch_game.py. - Serve the game files locally:
python3 launch_game.py- If you are on Linux or macOS, feel free to add a
#!/usr/bin/env python3shebang to the top of the file andchmod +x launch_game.py. This lets you launch the server more conveniently
- If you are on Linux or macOS, feel free to add a
- Navigate to
http://127.0.0.1:8000in a Web browser to play.
Footnotes§
The Wayback Machine uses Wombat for all its client-side URL rewriting needs.
See the MDN Web Docs entry for Access-Control-Allow-Origin
for details.
In the real published game, this query string corresponds to the md5sum
of the game asset we’re trying to retrieve. This doesn’t matter to us,
though; our dumb Python Web server ignores and discards the query string
anyway.